In the above diagram, the entire CI/CD is taken care of by Jenkins which is a 3rd party tool. In the real world, this required additional resources (infrastructure) and a team to manage this.
So, since We are using GitHub is there a way we can reduce this additional stuff. Yes, we can use GitHub Actions where the entire CI/CD will run on the same platform. We all have seen this option in GitHub but very rarely do we go there.

To understand it better, let's build a sample Spring Boot application --> Push the code in GitHub -->Trigger Github Actions --> Docker hub.
First, we need to create a repository in GitHub and then go to the Actions tab and click new Workflow options, here we will get many workflow options that we want to integrate with our application, but for this demo, we need to select " Java with Maven".

After you click on configure it will create a maven.yml file which you need to merge with your code, but before that, we need to update the yml to support our application build.

and yes that's it so whenever we merge the code in the master branch the GitHub Actions workflow will trigger and build the code, but we want is that after building the code the, latest changes should also deploy to the Container Registry I am using Docker here, but you can use any other.
In order to push the changes to the docker, we first need to create a repository in the docker hub and after that, we need to tell our maven.yml file about this new step.
# This workflow will build a Java project with Maven, and cache/restore any dependencies to improve the workflow execution time
# For more information see: https://help.github.com/actions/language-and-framework-guides/building-and-testing-java-with-maven
name: Java CI with Maven
on:
push:
branches: [ "master" ]
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
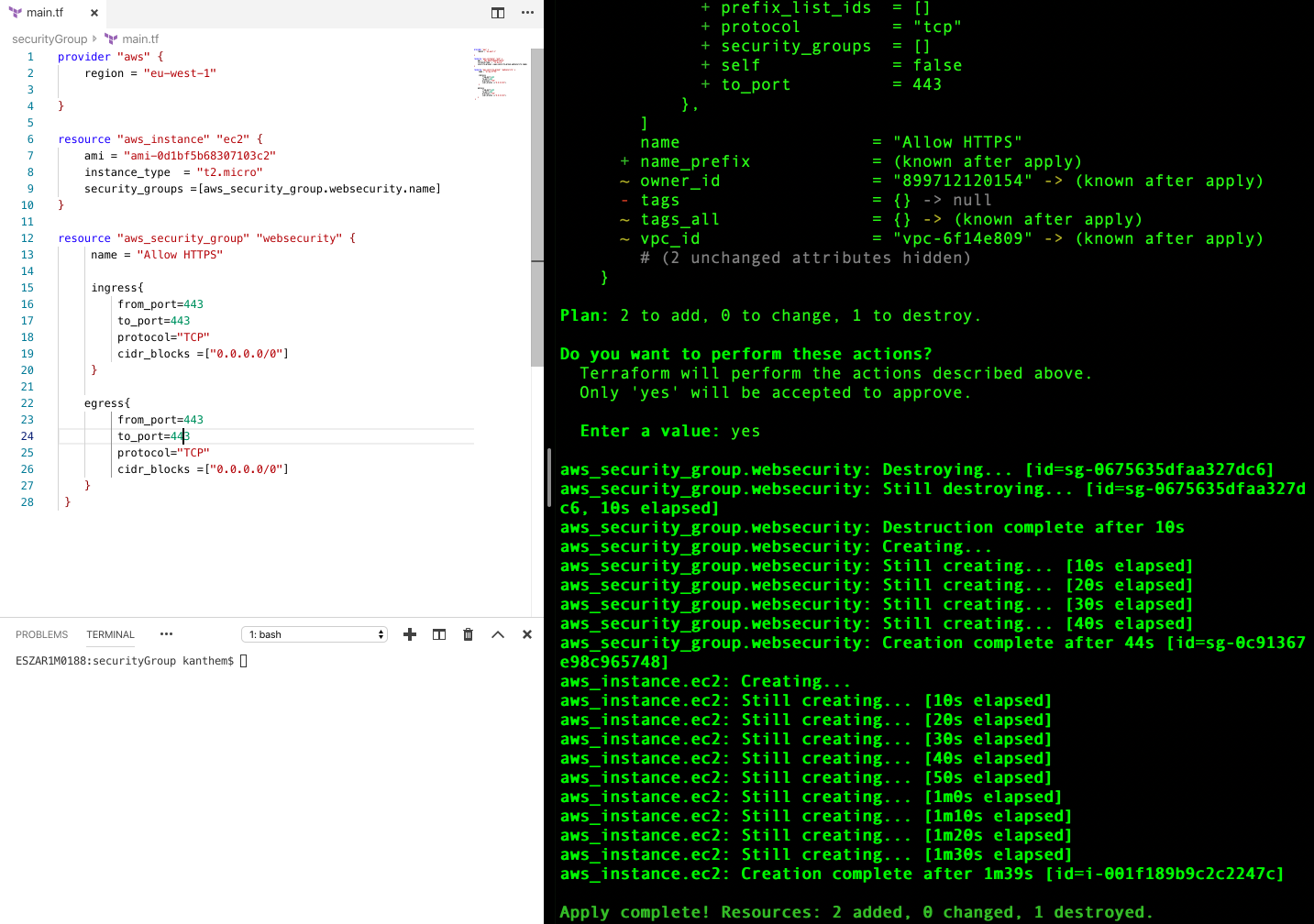
java-version: '17'
distribution: 'temurin'
cache: maven
- name: Build with Maven
run: mvn clean install
- name: Build & Push Docker Image
uses: mr-smithers-excellent/docker-build-push@v5
with:
image: hemkant/github-actions
tags: latest
registry: docker.io
dockerfile: Dockerfile
username: ${{ secrets.DOCKER_USERNAME}}
password: ${{ secrets.DOCKER_PASSWORD}}
I have used another image here which will perform all the operations docker-build-push. after that, the credentials to access the docker hub is stored in GitHub secrets.

After all of these let's commit some code and see, how all these work together. In the below screenshot, we can see all the workflow triggers whenever I committed the code.
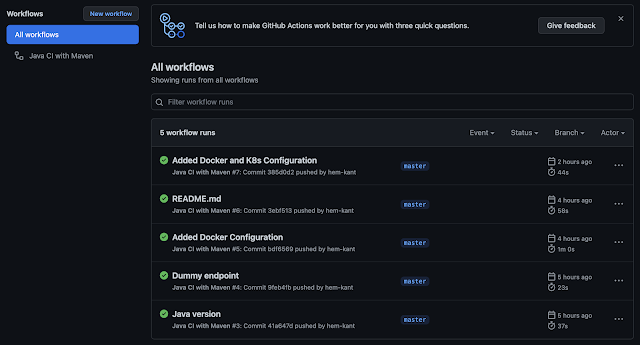
and let's also see if the steps we mentioned in our maven.yml file are followed or not, for that we can click on any item to check and it will show us all the details.

And the docker file which I used here is
FROM openjdk:17
EXPOSE 8080
ADD target/github-actions.jar github-actions.jar
ENTRYPOINT ["java", "-jar", "/github-actions.jar"]
let's check the Build & Push Docker Image step. looks like everything is fine here, and image is pushed to Docker Hub
The last thing we should also check is Docker Hub, looks good the image is pushed successfully.

We have covered all the points which we discussed at the beginning of this blog. Code Repo.
In the next blog, We will deploy the same image on the Google Cloud Platform, Kubernetes.
Happy Coding and Keep Sharing!!